|
Hyelin Nam I'm a PhD Student in Computer Science and Engineering at the University of Michigan, where I'm advised by Prof. JJ Park. Before that, I completed my master's at KAIST, where I was advised by Prof. Jong Chul Ye. Recently, I have worked on video diffusion models, exploiting their controllability to better capture physically plausible dynamics in generated videos. Moving forward, I am interested in extending these models toward world modeling and broader science-driven applications, including robotics. |
 |
Research |

|
[P2] SierpinskiCam: Camera-Controlled Video Retaking with Sierpinski Triangle Pattern Cues Suttisak Wizadwongsa*, Hyelin Nam*, Supasorn Suwajanakorn, Jeong Joon Park arxiv, 2026 project page / arXiv A camera-controlled video retaking method that improves geometry guidance with Sierpinski triangle pattern cues and reference-video conditioning. |

|
[P1] Generating Human Motion Videos using a Cascaded Text-to-Video Framework Hyelin Nam, Hyojun Go, Byeongjun Park, Byung-Hoon Kim, Hyungjin Chung arxiv, 2025 project page / arXiv A cascaded framework that bridges Text-to-Motion and video diffusion models for coherent, camera-aware human video generation. |
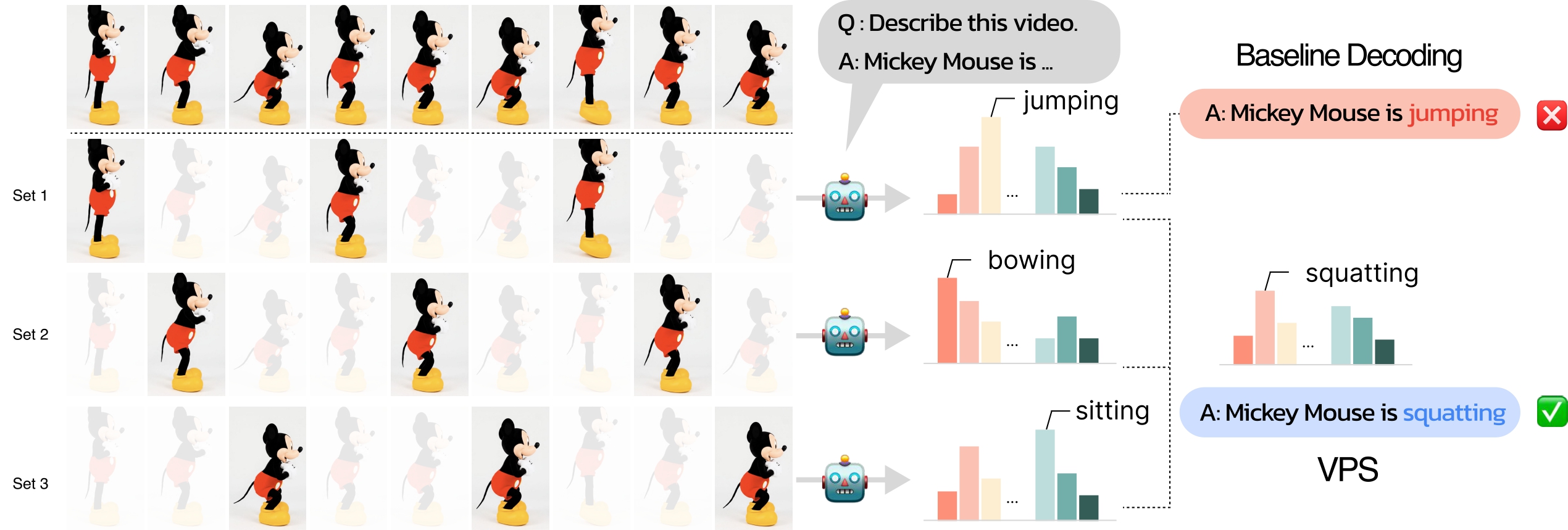
|
[C7] Video Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs Hyungjin Chung, Hyelin Nam, Jiyeon Kim, Hyojun Go, Byeongjun Park, Junho Kim, Joonseok Lee, Seongsu Ha, Byung-Hoon Kim CVPR Findings, 2026 arXiv / code An inference-time method that boosts VideoLLMs via parallel frame streams for richer temporal reasoning. |
|
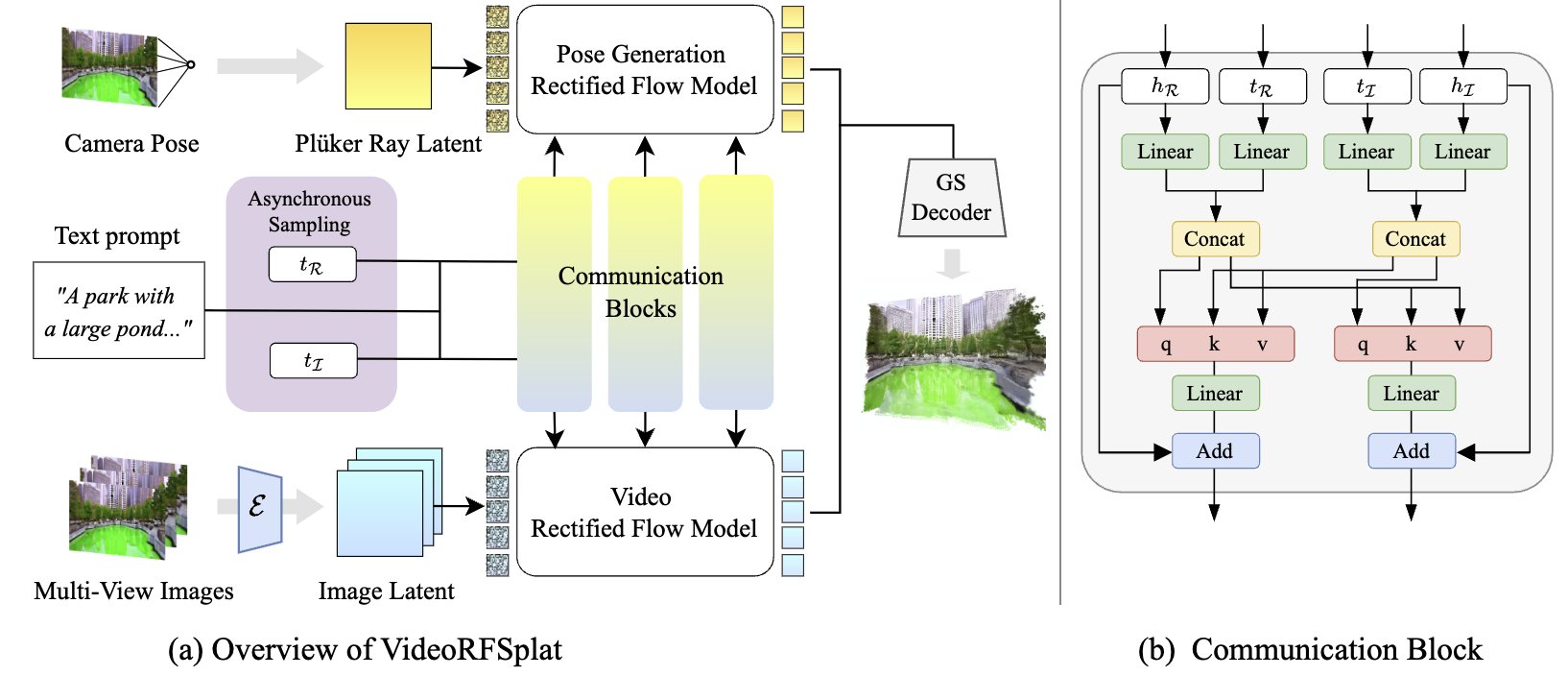
[C6] VideoRFSplat: Direct Scene-Level Text-to-3D Gaussian Splatting Generation with Flexible Pose and Multi-View Joint Modeling Hyojun Go*, Byeongjun Park*, Hyelin Nam, Byung-Hoon Kim, Hyungjin Chung, Changick Kim ICCV, 2025 project page / arXiv / code A text-to-3D method using a video generation model to jointly generate diverse camera poses and realistic 3DGS for unbounded scenes. |
|
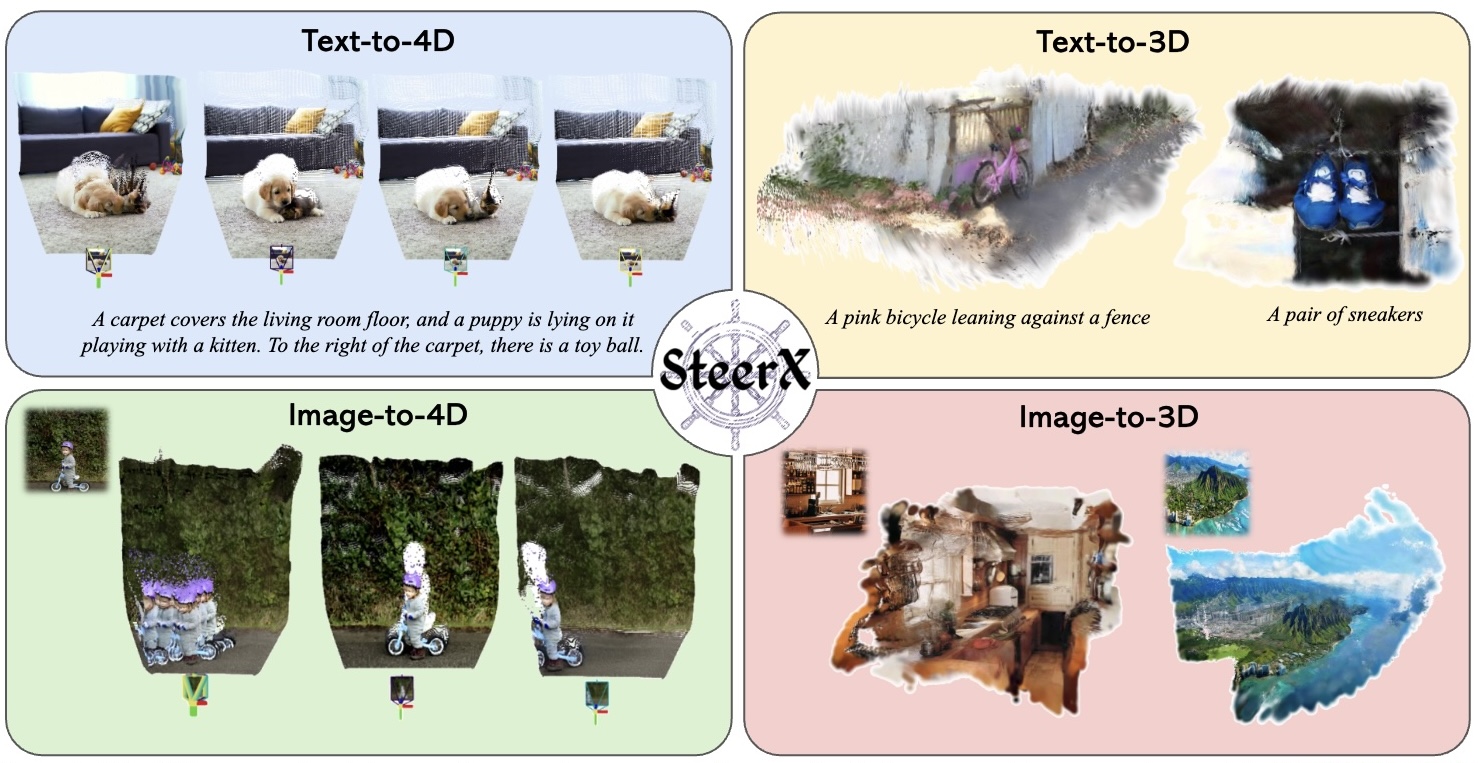
[C5] SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering Byeongjun Park*, Hyojun Go*, Hyelin Nam, Byung-Hoon Kim, Hyungjin Chung, Changick Kim ICCV, 2025 CVPR 2025 Workshop on WorldModelBench project page / arXiv / code A zero-shot inference-time steering method that enhances geometric alignment in 3D/4D scene generation by integrating scene reconstruction using pose-free geometric reward functions. |

|
[C4] Optical-Flow Guided Prompt Optimization for Coherent Video Generation Hyelin Nam*, Jaemin Kim*, Dohun Lee, Jong Chul Ye CVPR, 2025 project page / arXiv / code Prompt optimization driven by an optical flow discriminator to enhance temporal consistency and natural motion dynamics in video diffusion models. |
|
[C3] CFG++: Manifold-constrained Classifier Free Guidance For Diffusion Models Hyungjin Chung*, Jeongsol Kim*, Geon Yeong Park*, Hyelin Nam*, Jong Chul Ye ICLR, 2025 Silver prize, 31st Samsung Humantech Paper Award project page / arXiv / code A simple fix to CFG that enables lower guidance scales, improves sample quality and invertibility. |

|
[C2] Contrastive Denoising Score for Text-guided Latent Diffusion Image Editing Hyelin Nam, Gihyun Kwon, Geon Yeong Park, Jong Chul Ye CVPR, 2024 project page / arXiv / code Ensure structural correspondence by leveraging diffusion features during the score distillation process. |
|
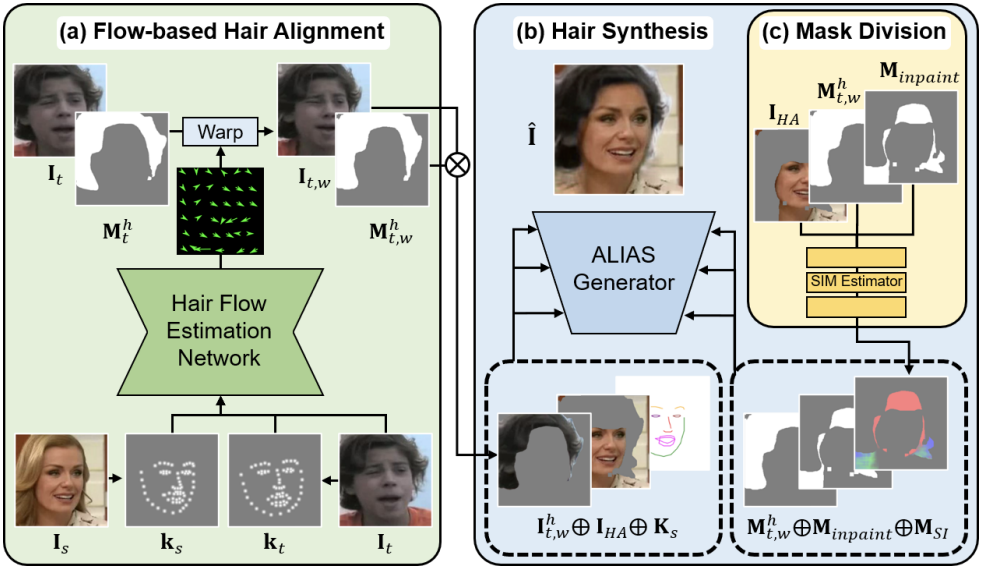
[C1] HairFIT: Pose-invariant Hairstyle Transfer via Flow-based Hair Alignment and Semantic-region-aware Inpainting Chaeyeon Chung*, Taewoo Kim*, Hyelin Nam*, Seunghwan Choi, Gyojung Gu, Sunghyun Park, Jaegul Choo BMVC, Oral Presentation, 2022 Best Paper Award, Korean Artificial Intelligence Association, 2021 arXiv |